音声対話の仕組み
音声対話処理
一般的に音声対話を実現するためには、
1. ユーザーの声を拾って、音を文字列に変換する
2. 1.で認識した文字列から、応答を選択・作成する
3. 2.の応答を音声にして再生する。
という一連の処理が必要になります。
ACUAH は、この一連の処理を以下の3つの対話方法から選んで設定する事ができます。
- 対話シナリオ(Scenario)
- LLM
- LLM Function calling
それぞれの対話方法について後述しますが、ACUAHでは対話方法により、音声対話、機能の実行、学習、親愛度・感情値の変化 という点で違いがあります。
| 対話方法 | 音声対話 | 応答音声(録音音声) | 応答音声(音声合成) | 機能の実行 | 学習 | 親愛度・感情値の変化 |
|---|---|---|---|---|---|---|
| 対話シナリオ(Scenario) | △ | ○ | × | ○ | ○ | ○ |
| LLM | ○ | × | ○ | × | × | × |
| LLM Function calling | ○ | × | ○ | ○ | ○ | ○ |
○:可能・あり △:可能・あり(制限あり) ×:不可能・なし
ユーザーご自身のキャラクターとの音声対話イメージから、対話方法を選択・設定してみてください。
- 話しかける言葉に制限があるが、録音音声を楽しみたい場合や機能を正確に実行させたい場合 は 「対話シナリオ(Scenario)」
- AIを使用した 音声対話だけを楽しみたい場合 は 「LLM」
- AIの良さを活かしながら機能の実行もさせてみたい場合 には 「LLM Function calling」
音声認識について
- ACUAHは スマートフォンのOS(Android, iOS)が標準で搭載する デバイスローカル版の音声認識エンジンを利用しています。
- ACUAHの音声認識エンジンは スマートフォンOSのシステム言語設定に依存しています。
- 日本語以外の言語でキャラクターに話しかけたい場合は、スマートフォンのシステム言語設定を変更 してください。
- 対話方法が「LLM」、「LLM Function calling」で、キャラクターの音声を日本語以外の言語にする場合には Microsoft Azure AI Speech のAPIキーが必要です。詳細は、Voice APIについて を参照してください。
設定例
ACUAHのキャラクターとAI(LLM)を使った英会話を楽しみたい場合
- スマートフォンのシステム言語を"英語(en-US)"等に変更する。(ACUAHは起動すると英語版として動作します。)
- 取得したMicrosoft Azure AI Speech の APIキーを設定する。
- キャラクターの音声として英語の音声("en-US-AnaNeural"等)を設定する。
対話シナリオ(Scenario)
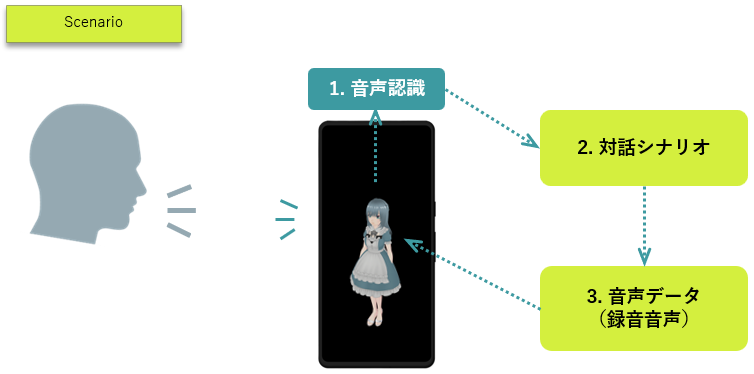
- 対話シナリオ とは、文字列とその文字列に対する応答内容が書かれた表 のようなものです。
(例)
| 文字列 | 応答内容(動作) |
|---|---|
| こんにちは | 手を振って「今日は」という音声を再生する |
| 今日は | 手を振って「今日は」という音声を再生する |
| おはよう | 手を振って「お早う」という音声を再生する |
| ・・・ | ・・・ |
これは、従来の 「ルールベース」 と言われる処理です。
- ユーザーが ACUAHに話しかけると、スマートフォンの音声認識エンジンが、ユーザーの声(音)を文字列に変換します。
- 変換された文字列が、対話シナリオ(表)にあるか確認します。
- 応答内容(動作)に従い音声データを再生します。(対話シナリオに該当文字列がない場合には、「分かりません。」と応答します。)
該当文字列が無い場合には「分かりません。」という素っ気ない対応になってしまう事が音声対話としては課題ですが、決まった文字列には決まった動作を正確に行えるという点が最大のメリットとなります。
LLM
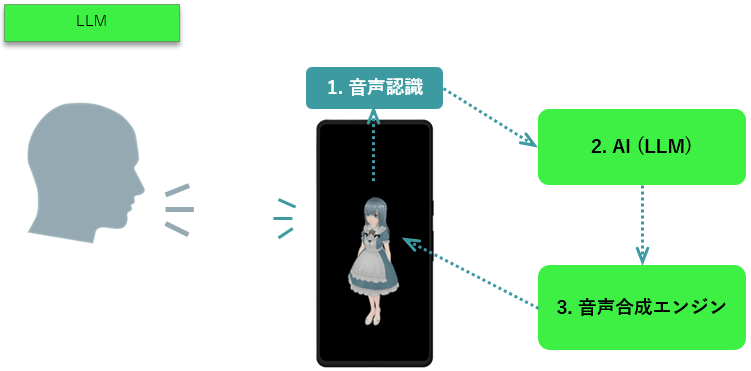
- LLM とは、昨今のAI(人工知能)技術において大規模言語モデル(Large Language Model)と呼ばれるものです。任意の文字列を入力すると、それに対する応答文をまるで人間のように生成して回答してくれます。代表的なLLMとして以下のようなものがあります。
- ChatGPT, Gemini, Claude, Llama, Grok
- 音声合成エンジン とは、文字列から音声(人の声)を生成する仕組み です。代表的な音声合成エンジンとして以下のようなものがあります。
- VOICEVOX, CeVIO AI, Microsoft Azure AI Speech
- スマートフォンの音声認識エンジンが、ユーザーの声(音)を文字列に変換します。
- 変換した文字列を、AI(LLM)に入力します。
- AI(LLM)から出力された文字列を、音声合成エンジンで処理し、音声として再生します。
この仕組みでは、ユーザーの音声(様々な文字列)に対して何かしらの応答を返す事が可能である一方、AIの応答が正しくない場合がある という点が課題となります。
LLM Function calling
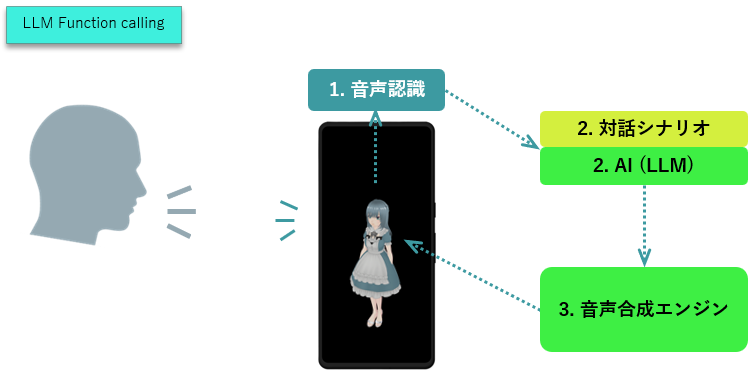
- LLM Function catlling とは、前述のLLMの応答の中に、機能の実行が含まれる ようになっているものです。
- AI(LLM)が文字列だけではなく、どの機能を実行するかという情報まで含んだ応答を生成します。
- スマートフォンの音声認識エンジンが、ユーザーの声(音)を文字列に変換します。
- 変換した文字列を、対話シナリオとAI(LLM)に入力します。
- 2.で 実行する機能を含んだ文字列が出力されます。併せて応答音声を 音声合成エンジンで処理し再生します。
(例)
ユーザー :「明日、8:15に起こして。」
AI(LLM):「了解」
AI(LLM):"SetAlarmClockというプログラムを実行。時間は8:15で設定すること" → 8:15に目覚ましが設定される。
この仕組みでは、キャラクターと音声対話をしながら機能を実行する事が可能な一方、AIの応答が正しくない場合がある ことから、誤った機能が実行される可能性がある点が課題となります。
ACUAH では、LLM Function callingは対話シナリオ と組み合わせたハイブリッドで処理をする仕組みになっています。